
How Much Should I Care When Language Chatbots Get Stuff Wrong?
How Much Should I Care When Language Chatbots Get Stuff Wrong?
a review of the "Membot" chatbot from the Memrise language app

As most of us have learned already by now, chatbots like ChatGPT (OpenAI), Bard (Google) and Bing (Microsoft) are great at predicting which word should come next when given a prompt; but completely lack any understanding of whether the words they say are true or not. If you ask a chatbot to prepare your legal defense, write a scientific paper, or even to spot the difference between text written by humans or machines, you should expect to be disappointed.
The sub-heading at that last link perfectly sums up my topic today:
If getting stuff right is such a deal breaker, why are we still so deep into this ML hype?
- Katyanna Quach
That’s a question I’ve been seriously asking myself over the past couple of weeks, after my Memrise language app updated itself to the latest early access version. It now includes the Membot chatbot, based on GPT-3 (OpenAI), that will talk you through a number of common scenarios in your chosen language, gently correcting your grammatical errors and supplying hints if you forget your words. Here it is in action, with a snippet from the scenario of haggling over the price of a rug. Membot’s lines in the role of the shopkeeper are given with a blue background:
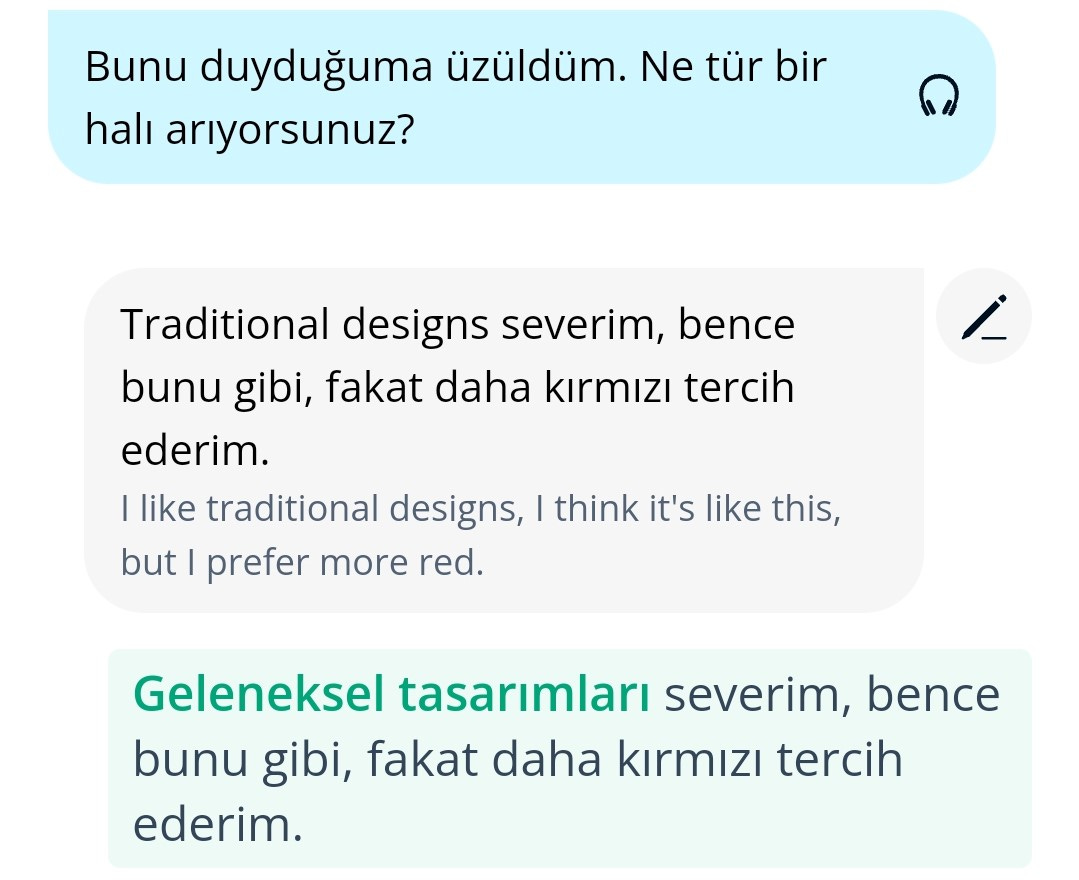
When replying to Membot’s question “what type of rug are you looking for?” (blue background in the screenshot), I couldn’t think how to express the idea of “traditional designs” in Turkish, so I just typed those words in English (off-white background). Membot then supplied the missing phrase “geleneksel tasarımları”, correcting my reply (in green).
You can even interrupt the roleplay and ask it a question addressed directly to “Membot”, and it will reply appropriately out-of-character. I asked it a few questions regarding its tolerance for swearing and offensiveness, and it cheerily assured me that I could say whatever I liked. For Science, I then said something very rude to Membot as it played the role of a little old lady at the bus-stop, and it firmly ended the scenario and invited me to try again in a more respectful way.
(Yes, the little old lady wasn’t real, but I still felt absolutely terrible doing this. I’ll come back to this later.)
Membot’s own replies are always relentlessly cheery and positive, which does mean it has to re-use some very generic responses occasionally. For example, “Vay canına, kulağa çok eğlenceli geliyor!” (“oh wow, that sounds like so much fun!”) comes up a lot for me. However, it has apparently been instructed to use a humorous tone whenever you ask it for help, and it has lot of creative autonomy with its hints. Here, I started a random scenario and immediately pressed the “hint” button:
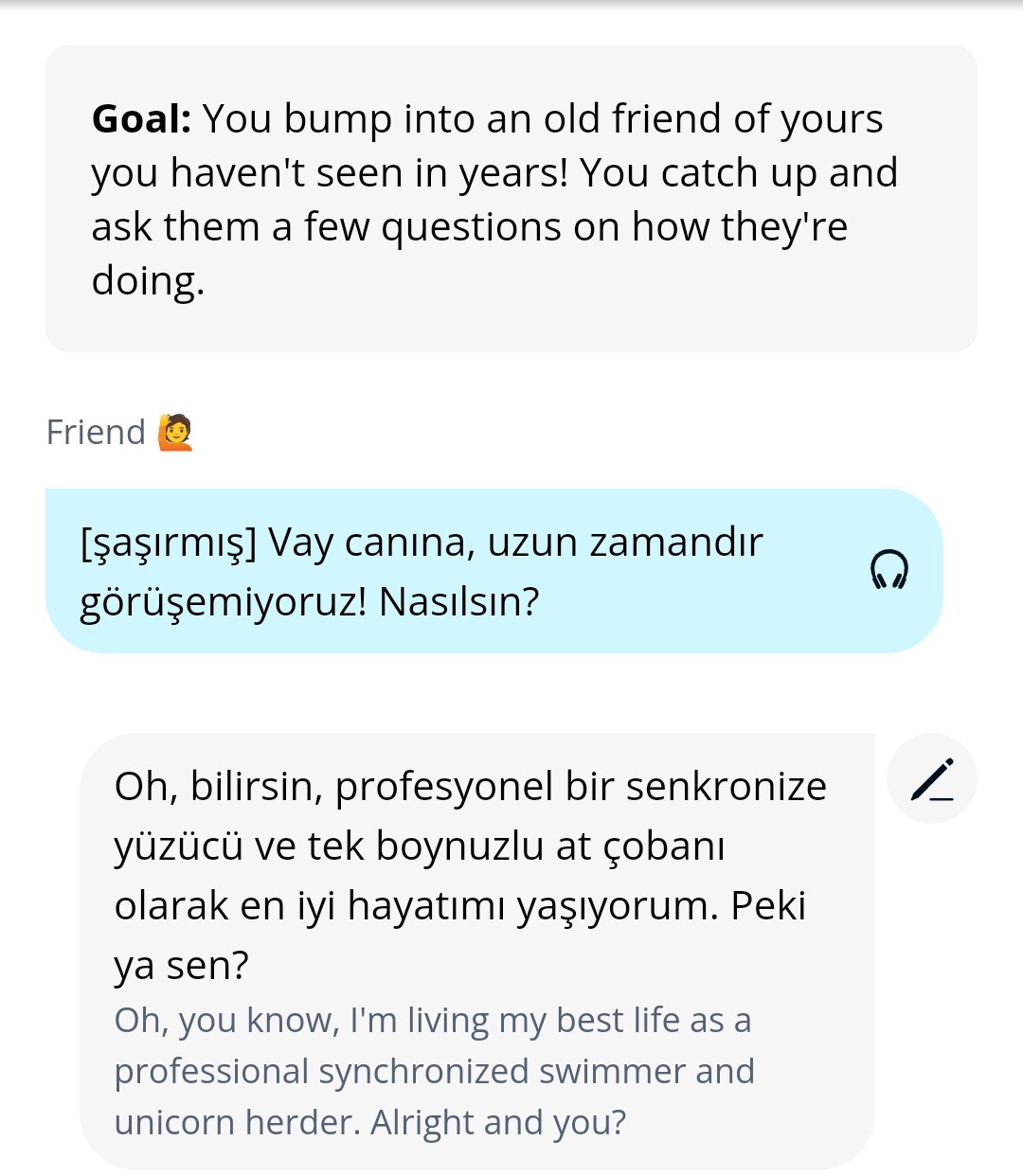
Restarting the scenario a few times, I got various similar auto-generated suggestions, that would match a prompt like “base your reply around a whimsically inventive occupation”; chicken-juggler, astronaut, another one about unicorns, and so on. I do like how light-hearted and non-scary this makes the whole thing; you’re not afraid to make mistakes when chatting with the AI, and you know you won’t be judged for accidentally saying something weird.
Opening your mouth for the first time in a new language is a big barrier to overcome for me (and I’m sure many others). I vividly remember arriving in various foreign countries, and how daunting it was to use the strange new words you’d been practicing, in a real situation for the first time.1 In fact, some of these incidents are burned permanently into long-term memory, such that I think I can remember the exact words I said at the time. I feel that chatbots like Membot offer genuinely useful practice here, especially for anyone who is a bit anxious or otherwise lacks confidence.
You could already do this type of thing for yourself if you were to sit down and talk to ChatGPT, but this app takes all the prompt engineering out of it. The scenarios are all ready to go; the chatbot has been told what it’s role is and how to respond, and that it should correct the user’s grammatical and spelling errors. It will apparently even be available for free; non-subscribed users will be able to use it on release (I believe you need to pay for early access).
I love it so far, which is what makes me so conflicted. How do I trust Membot’s accuracy? What if it teaches me some point of Turkish grammar that is completely wrong, and I try to use it in the real world and suffer a moment of slight embarrassment?
It’s not the self-contradictory hallucination-type errors that I fear; those are easy to spot. Here’s Membot changing it’s mind about the correct spelling of a couple of words:

Like I said: it’s easy to spot if the chatbot contradicts itself within the space of two lines, and you can quickly tab out to a dictionary to check if you’re not sure.
Similarly, crude contextual errors are easily noticeable. Let me swap focus back to the Drops app for a moment, whose quiz AI sometimes makes mistakes that confirm that it “thinks” in English; confusing the colour “orange” with the name of the fruit, for example, when the target language (in this case Turkish) uses two different words in these contexts. Here’s another example of a homonymous contextual error from this morning’s Drops quiz:
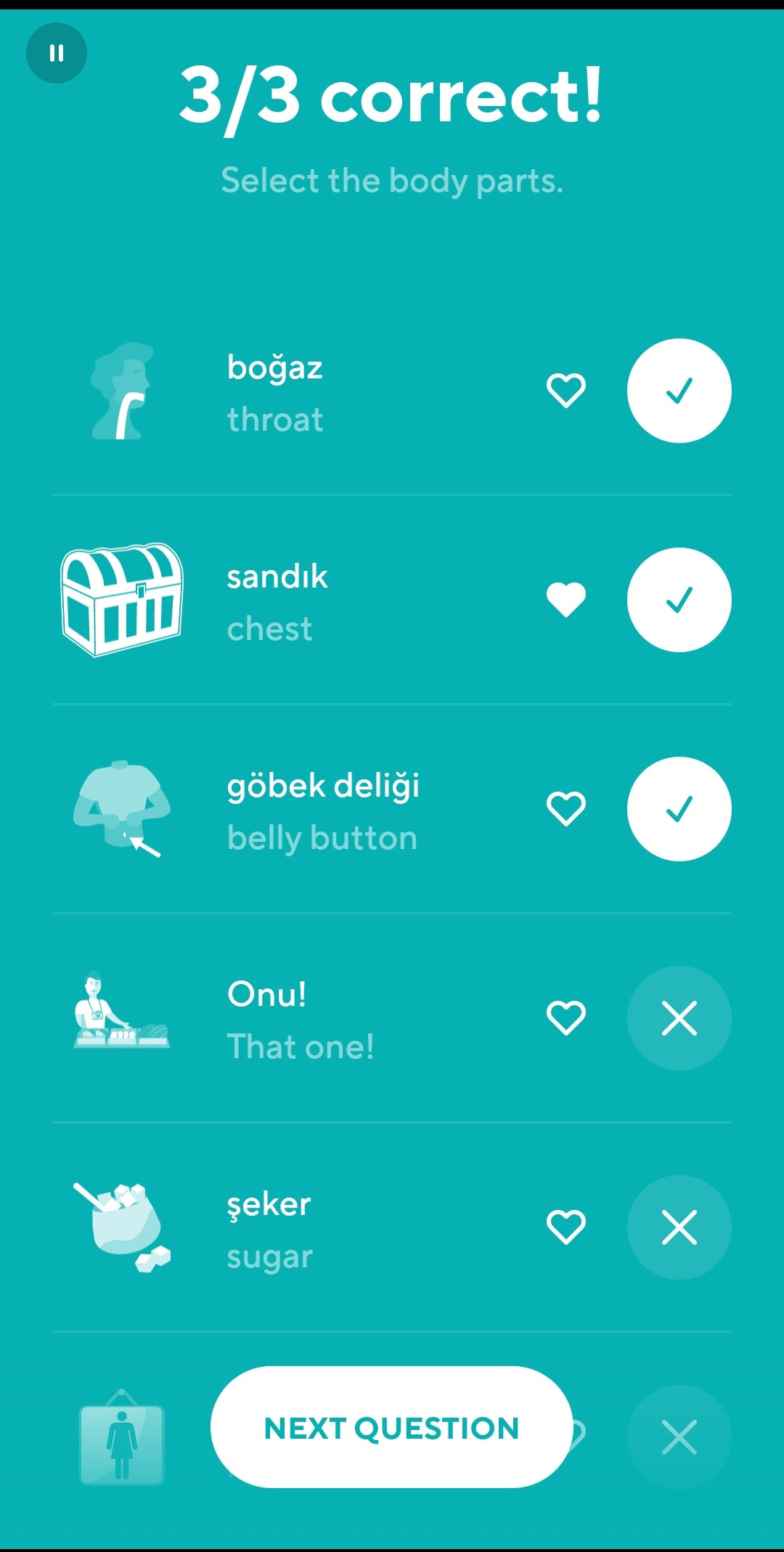
Your score in the Drops quiz games is just a number (you could share it on social media if you felt like it), so it wouldn’t have mattered to me if I had been fooled by the error and chosen incorrectly. This is “the Devil you know”; the failings of the AI that you are aware of and can see through, and can therefore accommodate. Working through this type of error can even be helpful! The filled heart next to the word “sandık” means I had previously favourited it as a word I find particularly hard to remember; after working through this error I’ll have an extra mental hook to hang the word “sandık” on, and maybe I’ll remember it better next time.
No, the obvious errors don’t matter, nor the random hallucinations which are unlikely to be repeated often enough to stick in my mind. It’s the more subtle mistakes that concern me, the ones I don’t pick up on. “The Devil you don’t”, or Donald Rumsfeld’s “unknown unknowns”, I guess. I know these must exist, because I see some mistakes that are subtle enough that I almost miss them. Here’s one that came close, from the scenario with the rug-seller excerpted above:
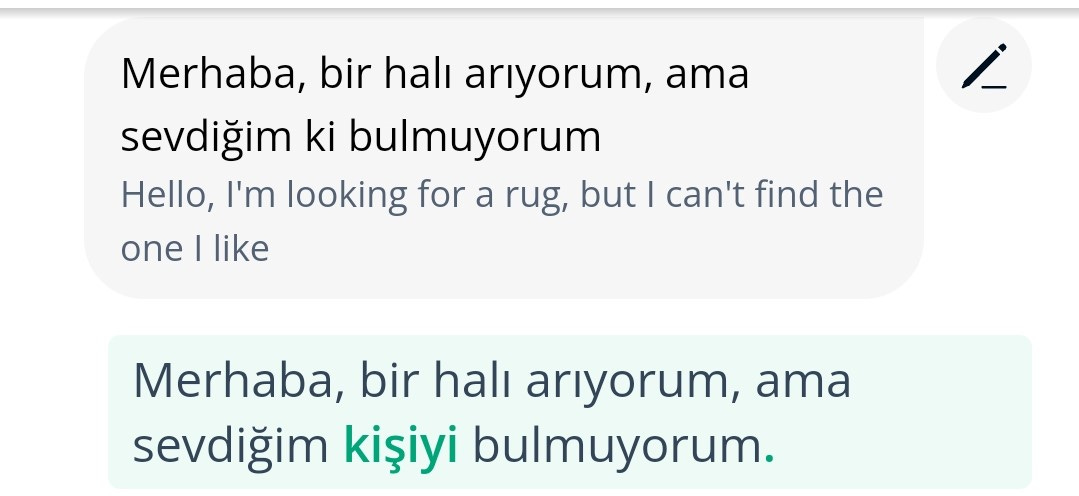
My initial greeting to the imaginary rug-seller turned out close to what I intended, but didn’t quite get there. In fact, Membot’s auto-translation of my input matches my intent closely: “Hello, I’m looking for a rug, but I can’t find the one I like”. However, there is a subtle error in Membot’s understanding and it’s supplied correction (in green).
I don’t have a good intuitive grasp of the Turkish particle/suffix “ki”. I dimly know a few examples, such as “benim” = “mine”; “benimki” = “the one that is mine”. You can see where I was going - “sevdiğim ki” = “the one that I like”. Maybe this construction even makes some sense in Turkish, but in hindsight at least, I should have just gone with “sevdiğimi”.
Even so, “sevdiğimi” is maybe too strong an emotion for talking about a rug (Google Translate chooses “beğendiğimi” instead). Perhaps because of this, Membot has failed to grasp that “the one I like” refers to the rug. Its auto-correction “sevdiğim kişiyi” literally means “the one (person) I like”. Whereas to me “the rug” and “the one I like” refer to the same object, to Membot they are two different grammatical objects, one of which is human. It’s a standard error for an AI; not interpreting context around ambiguous statements in the same way that a human would.
Luckily I already knew the word “kişi”,2 but for a moment I assumed Membot’s usage was correct, mostly because Membot’s auto-translation of my input seemed to match what I was trying to say. What other mistakes and misunderstandings might Membot be feeding me, that are subtly teaching me incorrect Turkish? Since Membot is not my only exposure to Turkish, will Membot’s errors even matter? Or will they be corrected unnoticed in my mind, by exposure to other sources?
In short, given that “chatting” is the thing a chatbot should do best, I feel the benefits of having a machine in your pocket that can chat to you in Turkish whenever you have a spare moment outweigh the risks of hearing something incorrect (you can quote this as my official review of Membot). After all, humans can stutter or misspeak or lie or introduce many other errors when they talk to each other. Is there any reason to think there would be some special extra risk with machine errors? Something like the harms we ascribe to social media, that only became more obvious over time?
This all goes back to a question I’ve been interested in since my very first post. Will useful stuff like “understanding context like a human” just spontaneously develop when we scale up our existing Large Language Models? Just making them bigger; no other changes? Or is there something missing, something additional that must be built in before we can trust AIs to educate ourselves and our children?
There are two camps in this argument, typified by these two recent articles; the pessimist view (Matt O’Brian at AP), and the optimist view (Ari Schulman at The New Atlantis). Both articles state their case well for the future of chatbots, and how we will come to grips with this technology as it evolves. And evolve it will; remember Membot is based on GPT-3, but inevitably they will update it to use GPT-4 in time. I’ve never used GPT-4, but some of the stories coming out about its capabilities are intriguing.
The pessimist, skeptical view is that future versions of GPT will be the same stochastic parrot that GPT-3 currently is, only bigger and better. There is no understanding, only AIs repeating stuff that was in their training data. We will learn to deal with this the same way we deal with typos that humans make, by employing editors, spell-checkers and so on. The pessimist article quotes Sam Altman (CEO of OpenAI) regarding his own company’s technology:
I probably trust the answers that come out of ChatGPT the least of anybody on Earth […] I think we will get the hallucination problem to a much, much better place. I think it will take us a year and a half, two years. Something like that. But at that point we won’t still talk about these. There’s a balance between creativity and perfect accuracy, and the model will need to learn when you want one or the other.
If that’s how future Membot turns out, then fine; I can work with that. I’ll keep using it as a tool, while learning to accommodate its faults, same as any other tool. Remember the error that nearly caught me above resulted in part from the ambiguity in my phrase “the one”. Just as I’ve had to learn to spell things out more carefully when communicating by email where you can’t take advantage of prosody, I’ll have to be aware that AIs can’t (yet) do prosody either. Or body language or in-jokes or any number of non-verbal communication styles.
...But the optimistic view says that future Large Multimodal Models will handle these things. As the optimist article points out, the power of the Transformer paradigm (the “T” in GPT) is that it can convert anything - everything - into an encoding that manipulates natural language.
GPT-4 can therefore take images as input, in addition to text. It doesn’t process them separately, just Transforms them into the same encoding as text inputs, and deals with both together. Here’s an example:

Maybe it will handle the problem I discussed in my first ever post; that of adding gendered pronouns back in to English subtitles, when translating from Turkish which has no grammatical gender. If someone is referred to on-screen as “The Governor of Kulucahisar”, then their genderless Turkish 3rd-person pronoun “o” doesn’t contain the information needed to choose between he/she/they/etc. in English. You can only resolve this by visual clues (in that example, the Governor’s dress, makeup and tiara, and the historical period portrayed, strongly suggest you should go with “she”).

And really, none of us have a good handle on “the truth”. Worries about susceptibility to conspiracy theories, information warfare and election interference, and censorship of online misinformation all suggest we fear that humans have no understanding of whether their own words are true or not. We just arrive at “the truth” by inference from all the sensory and information inputs we take in. Call that our “training data” and our own capabilities start to look less special.
Some of the fears around the rise of sentient machines may in fact result from the deflation of our own egos, upon realising we would no longer be special and unique. But equally deflating would be the realisation that sentience wasn’t even required when building a human-level intelligence. This echoes philosopher/neuroscientists like Thomas Metzinger, Daniel Wegner and Oliver Sacks, who inspired the writer Peter Watts to say:
[…] at least under routine conditions, consciousness does little beyond taking memos from the vastly richer subconcious environment, rubber-stamping them, and taking the credit for itself. In fact, the nonconscious mind usually works so well on its own that it actually employs a gatekeeper in the anterious cingulate cortex to do nothing but prevent the conscious self from interfering in daily operations. (If the rest of your brain were conscious, it would probably regard you as the pointy-haired boss from Dilbert.)
Just look at how (non-sentient) GPT-4 deals with context, compared to GPT-3’s Membot error discussed above:


Commenting on this example, Ari Schulman says:
Yes, ChatGPT does not have the full capacity for closed reasoning […] — the ability to describe the entire chain of logic behind an answer, and the cold rational trustworthiness that comes along with this. But what it can do is make implicit context explicit, and attempt to correct itself (often imperfectly) when its errors are noted. It displays an open-ended capacity to respond. It can account for itself.
ChatGPT is already sounding like a half-decent scientist. Current AIs process text, images and sounds using the same Transformer paradigm, but there’s no impediment to encoding any other data in that way - radio waves, global temperature data, the Cosmic Microwave Background. In the future my job as a scientist may look very different…
So my rug-seller example above, about Membot failing to grasp context, is probably moot - similar examples of equal complexity are already fixed in GPT-4. Whether or not the optimists are correct and reasoning from available inputs is all there is to intelligence, we will still live through multiple iterations of GPT, each susceptible to hallucinations, contradictions and logical errors in its own way. The last thing I wanted to highlight from the Ari Schulman essay - which as you can gather I enjoyed very much - is his mindset for thinking about such errors. It’s one that resonates with us language-learners:
7. Its errors are not nonsense; they are alien.
Do transformers have a grasp of the world, or a posture toward it — or at least a persuasive imitation of the same?
Answering “yes” would help to make sense not just of the way the new AIs succeed, but also the ways they fail. Among other things, it would help to make some sense of the uncanny features that linger in the new flood of AI-generated images, audio, and video. Yes, much of this material still seems eerie, unnatural, inhuman. People in Midjourney images notoriously still have too many teeth or fingers, warped faces, funhouse smiles. An AI-generated beer commercial looks like a horrifying Banksy parody of American consumerism, if Banksy had talent.
But these kinds of errors seem hard to make sense of as mistakes of logic. They are easier to make sense of as a system working out the right place for parts among a coherent whole, and still making some mistakes of integration. They feel, in short, like elements lost in translation, the kinds of mistakes we would expect across the wide gulf between us and an agent who is not only not native to our language but not native to our bodies or our lifeworld, and yet who is making genuine strides at bridging that gulf. They seem like the mistakes less of a facile imitation of intelligence than a highly foreign intelligence, one who is stumbling toward a more solid footing in our world.
Firstly, in making sense of this I very consciously note my own brain’s tendency to anthropomorphise and ascribe sentience to chatbots, despite being completely convinced that they are not currently “real”. In real life I would never swear at an old lady at a bus-stop, and so I felt terrible while swearing at a chatbot pretending to be an old lady, for the purposes of this review. But the machine is not sentient (yet), and it “feels” no offence at my language at all; its admonishment of me is a learned response imposed by its handlers. I therefore try very hard not to feel things when I read emotive passages like that last quote, no matter how much I may enjoy picturing the “highly foreign intelligence, one who is stumbling toward a more solid footing in our world”.
But past the mental imagery lies a truth: we shouldn’t expect the machines to make human errors, because they are not human. That’s why the “hallucination” errors seem so strange to us; we can’t understand how a machine that spells “ıstakoz” correctly in one sentence but not the next, can be exhibiting intelligent behaviour. Think of it as a translation error though, between two languages (Turkish and machine code) so far apart as to be alien, and you’ll be less likely to be fooled. The machine uses ones and zeroes in a perfectly rational way, and logic works the same (we assume) throughout the universe. The machines have perfectly good reasons why they make the mistakes that they do; we just lack understanding of the weirdest ones. Thinking of these errors as “random” might be hiding just how far the machines have come, and how closely they follow behind us.
Vietnam was the hardest I think, as I’d learned very little Vietnamese. I wanted to greet the Customs official (who was to grant me a tourist visa on arrival) in his own language, but couldn’t get the words out. He did get a mangled “cảm ơn” (“thank you”) when he gave me back my passport, if I remember right.
Memrise had already taught me the extremely useful phrase “ iki kişilik bir masa lütfen” (“a table for two, please”)